PanelCallbackHandler#
Open this notebook in Jupyterlite | Download this notebook from GitHub (right-click to download).
The Langchain PanelCallbackHandler is useful for rendering and streaming the chain of thought from Langchain objects like Tools, Agents, and Chains. It inherits from Langchain’s BaseCallbackHandler.
Check out the panel-chat-examples docs to see more examples on how to use PanelCallbackHandler. If you have an example to demo, we’d love to add it to the panel-chat-examples gallery!
Parameters:#
Core#
instance(ChatFeed | ChatInterface): The ChatFeed or ChatInterface instance to render or stream to.user(str): Name of the user who sent the message.avatar(str | BinaryIO): The avatar to use for the user. Can be a single character text, an emoji, or anything supported bypn.pane.Image. If not set, uses the first character of the name.
Basics#
To get started:
Pass the instance of a
ChatFeedorChatInterfacetoPanelCallbackHandler.Pass the
callback_handleras a list intocallbackswhen constructing or using Langchain objects.
import panel as pn
from langchain.llms import OpenAI
pn.extension()
llm = OpenAI(temperature=0)
def callback(contents, user, instance):
callback_handler = pn.chat.langchain.PanelCallbackHandler(instance)
return llm.predict(contents, callbacks=[callback_handler])
pn.chat.ChatInterface(callback=callback).servable()
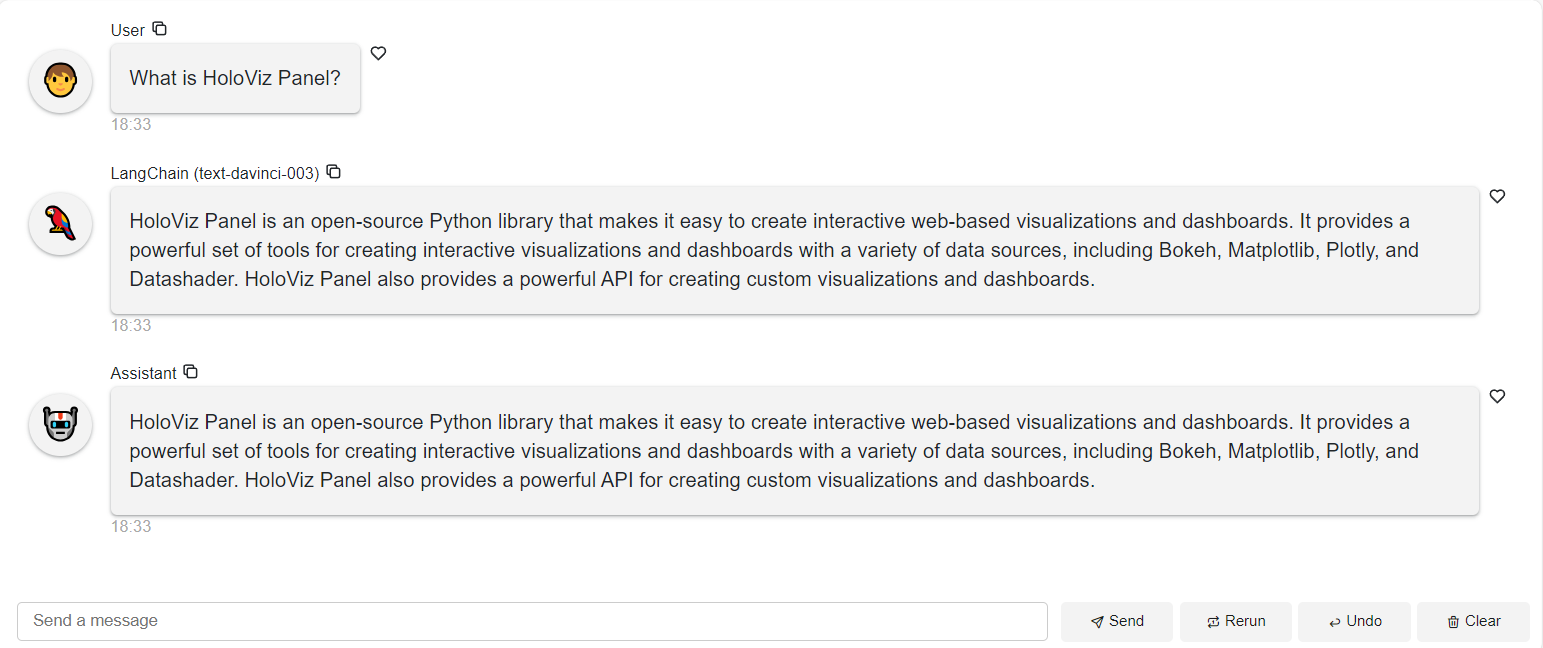
This example shows the response from the llm only. A llm by it self does not show any chain of thought. Later we will build an agent that uses tools. This will show chain of thought.
Async#
async can also be used. This will make your app more responsive and enable it to support more users.
import panel as pn
from langchain.llms import OpenAI
pn.extension()
llm = OpenAI(temperature=0)
async def callback(contents, user, instance):
callback_handler = pn.chat.langchain.PanelCallbackHandler(instance)
return await llm.apredict(contents, callbacks=[callback_handler])
pn.chat.ChatInterface(callback=callback).servable()
Streaming#
To stream tokens from the LLM, simply set streaming=True when constructing the LLM.
Note, async is not required to stream, but it is more efficient.
import panel as pn
from langchain.llms import OpenAI
pn.extension()
llm = OpenAI(temperature=0, streaming=True)
async def callback(contents, user, instance):
callback_handler = pn.chat.langchain.PanelCallbackHandler(instance)
return await llm.apredict(contents, callbacks=[callback_handler])
pn.chat.ChatInterface(callback=callback).servable()
Agents with Tools#
Tools can be used and it’ll also be streamed by passing callback_handler to callbacks.
from langchain.llms import OpenAI
from langchain.agents import AgentType, initialize_agent, load_tools
import panel as pn
llm = OpenAI(temperature=0, streaming=True)
tools = load_tools(["ddg-search"])
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True,
)
def callback(contents, user, instance):
callback_handler = pn.chat.langchain.PanelCallbackHandler(instance)
return agent.run(contents, callbacks=[callback_handler])
pn.chat.ChatInterface(callback=callback).servable()
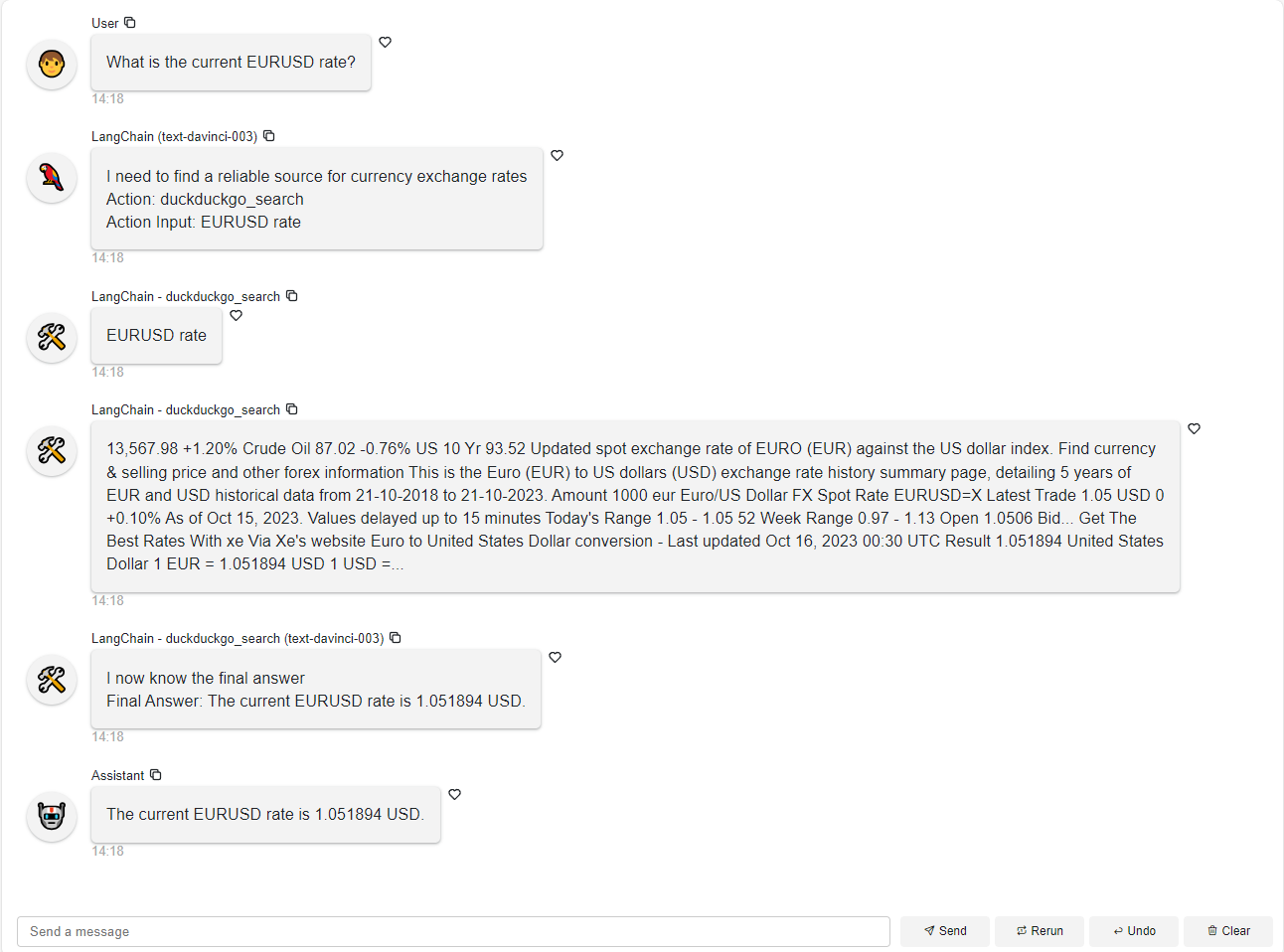
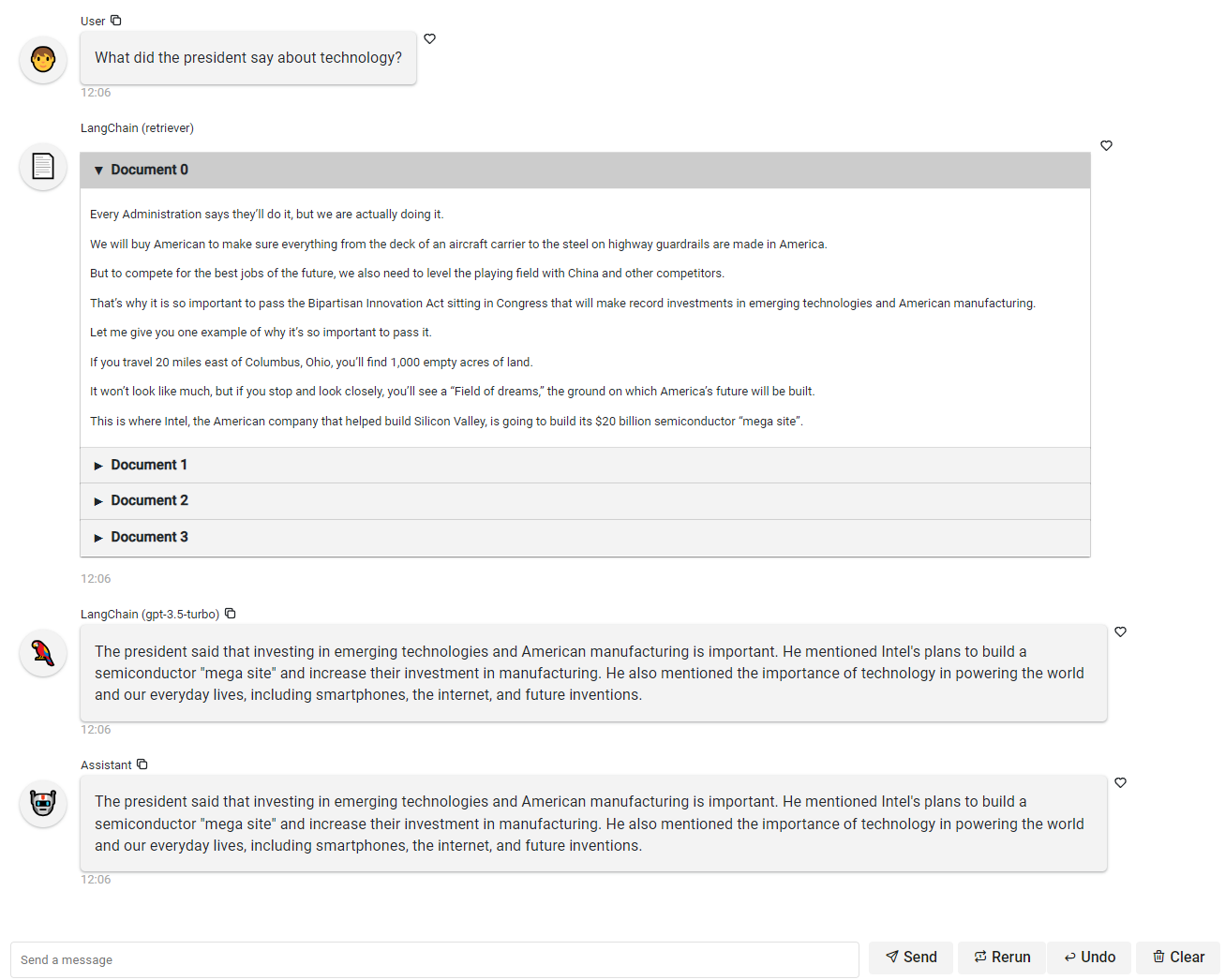
Chains with Retrievers#
Again, async is not required, but more efficient.
from uuid import uuid4
import requests
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
import panel as pn
TEXT = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
TEMPLATE = """Answer the question based only on the following context:
{context}
Question: {question}
"""
pn.extension(design="material")
prompt = ChatPromptTemplate.from_template(TEMPLATE)
@pn.cache
def get_vector_store():
full_text = requests.get(TEXT).text
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text)
embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
return db
db = get_vector_store()
def get_chain(callbacks):
retriever = db.as_retriever(callbacks=callbacks)
model = ChatOpenAI(callbacks=callbacks)
def format_docs(docs):
text = "\n\n".join([d.page_content for d in docs])
return text
def hack(docs):
# https://github.com/langchain-ai/langchain/issues/7290
for callback in callbacks:
callback.on_retriever_end(docs, run_id=uuid4())
return docs
return (
{"context": retriever | hack | format_docs, "question": RunnablePassthrough()}
| prompt
| model
)
async def callback(contents, user, instance):
callback_handler = pn.chat.langchain.PanelCallbackHandler(instance)
chain = get_chain(callbacks=[callback_handler])
response = await chain.ainvoke(contents)
return response.content
pn.chat.ChatInterface(callback=callback).servable()
Please note that we use the hack because retrievers currently do not call any CallbackHandlers.
See LangChain Issue#7290.
Open this notebook in Jupyterlite | Download this notebook from GitHub (right-click to download).

