Particle Swarms#

Interactive Particle Swarm Optimisation Dashboard from Scratch in Python#
Swarm Intelligence from social interaction
toc: true
badges: true
comments: true
categories: [jupyter, optimisation, visualisation]
Why are we here?#
I’m hoping it’s to read about Swarm Intelligence! I’m also hoping you’re interested to read about the interactive dashboard side of things too so we can play with it at the end.
Finding the “just right” Goldilocks Zone using Swarm Intelligence#
Say you’re building a house and you want to maximise the number of rooms you can fit in your plot of land, maybe saying that all rooms have to be a certain size or bigger. That’s the kind of thing that optimisation algorithms are useful for.
Optimisation methods like Particle Swarm Optimisation are used when you want to find the best/optimum for some system / problem. You could just try every possible input but that might take a while so smarter people than me have invented better ways.
Make it interactive because#
Let’s build a dashboard in which you can control parameters of Particle Swarm Optimisation, click a target and see the little dots flock towards it. Like an interactive, 2D version of this plot on Wikipedia.
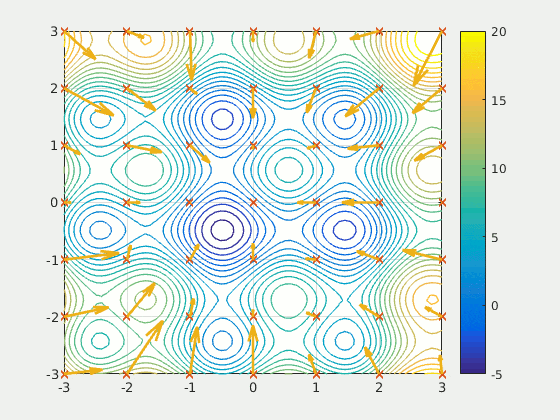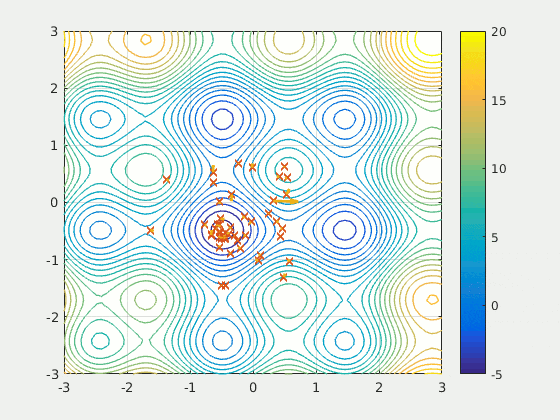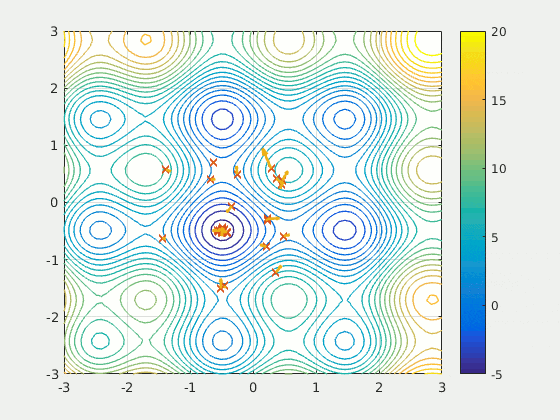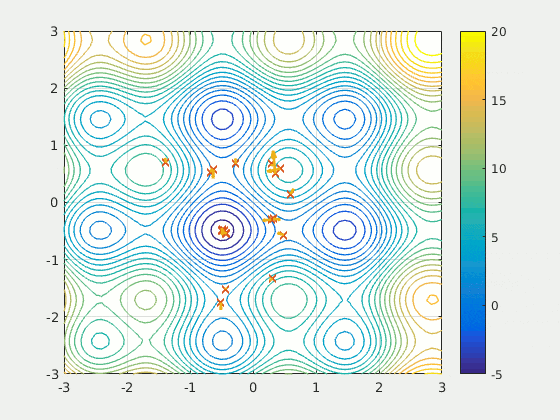
Swarm Intelligence#
## Wait, why no death?
Genetic algorithm is based on genetic evolution where each generation there is survival-of-the-fittest-style well… death. In the case of Particle Swarm Optimisation, there is the same population throughout because we want them to remember where they were when they were at their fittest. Like looking back at yourself on your wedding day or after a health kick. Each particles position is a potential solution to your problem so they’re all trying to find the best position together.
Adding velocity to the mix#
In the case of Genetic Algorithm each member of the population was just a few numbers (their X and Y position), the parameters that you’re trying to optimise. In this case each particle will not just have a X and Y position, they also have a velocity. We also need a way to know how to improve the particles in our swarm…
### Closer (smaller distance) is better
We’ll need to find the fittest member of the population using euclidean distance / mean squared error (which particle is closest to the target).
#collapse-hide
def mean_squared_error(y_true, y_pred):
return ((y_true - y_pred)**2).mean(axis=0)
target_x, target_y = 0,0
def problem(soln):
global target_x #using globals so we can link this to the click event later
global target_y
return mean_squared_error(soln, [target_x, target_y])
def assess_fitness(individual, problem):
"Determines the fitness of an individual using the given problem"
return problem(individual)
Nostalgic by design#
Each member is going to keep track of their fittest position, this can help them if they explore a worse direction, or want to tell other particles (but we’ll get to that later). They also keep an ID so that we can colour them across iterations.
Here’s that in code (before we add any of the update logic).
import numpy as np
import random
from holoviews import opts, dim
import holoviews as hv
import panel as pn
from holoviews.streams import Stream
hv.extension('bokeh', logo=False)
class Particle:
def __init__(self, problem, velocity, position, index):
self.problem = problem
self.velocity = velocity
self.position = position
self.fittest_position = position
self.id = index
Create a “swarm” of them#
For each particle, we want their position and velocity. We also convert their velocity into angle and magnitude for the little arrows in the visualisation.
vector_length=2
swarm_size = 50
swarm = [Particle(problem, np.random.uniform(-2, 2, vector_length), np.random.rand(vector_length), i)
for i, x in enumerate(range(swarm_size))]
Here’s what our swarm looks like:
def to_angle(vector):
x = vector[0]
y = vector[1]
mag = np.sqrt(x**2 + y**2)
angle = (np.pi/2.) - np.arctan2(x/mag, y/mag)
return mag, angle
def get_vectorfield_data(swarm):
'''Returns (xs, ys, angles, mags, ids)'''
xs, ys, angles, mags, ids = [], [], [], [], []
for particle in swarm:
xs.append(particle.position[0])
ys.append(particle.position[1])
mag, angle = to_angle(particle.velocity)
mags.append(mag)
angles.append(angle)
ids.append(particle.id)
return xs, ys, angles, mags, ids
vect_data = get_vectorfield_data(swarm)
vectorfield = hv.VectorField(vect_data, vdims=['Angle', 'Magnitude', 'Index'])
# [x, y, id] for all particles
particles = [np.array([vect_data[0], vect_data[1], vect_data[4]]) for i, particle in enumerate(swarm)]
points = hv.Points(particles, vdims=['Index'])
layout = vectorfield * points
layout.opts(
opts.VectorField(color='Index', cmap='tab20c', magnitude=dim('Magnitude').norm()*10, pivot='tail'),
opts.Points(color='Index', cmap='tab20c', size=5)
)
Note: Here we initialised the particles with a velocity for visualisationg, we’ll initialise them with zero velocity when it comes to actually optimising.
Updating#
Okay so we have a population of particles, each with a position, velocity and fittest position but how can we update this population to find our optimum spot.
Each particle could just move in the direction that they think the optimum spot is. But if they overshoot it or get lost, thankfully they remember their best position so they can use that a little bit too.
Find the fittest Particle in the swarm#
We use this find_current_best method to keep track of our current fittest Particle, and to find the best among a selected few “informant” Particles for the social component.
#collapse-show
def find_current_best(swarm, problem):
"""Evaluates a given swarm and returns the fittest particle based on their best previous position
This can be sped up to only loop over swarm once, but because this is a tutorial, 3 lines is nicer.
"""
fitnesses = [assess_fitness(x.fittest_position, problem) for x in swarm]
best_value = min(fitnesses)
best_index = fitnesses.index(best_value)
return swarm[best_index]
PSO Class#
This is just a wrapper which updates all the particles and keeps track of the current fittest.
Note: One thing to note is that we randomly sample the swarm to get the “informants” for the
socialupdate in each particle. There are many different topologies that can be chosen for this part of the algorithm, but we’re keeping it simple here.
class PSO:
"""
An implementation of Particle Swarm Optimisation, pioneered by Kennedy, Eberhart and Shi.
The swarm consists of Particles with 2 fixed length vectors; velocity and position.
Position is initialised with a uniform distribution between 0 and 1. Velocity is initialised with zeros.
Each particle has a given number of informants which are randomly chosen at each iteration.
Attributes
----------
swarm_size : int
The size of the swarm
vector_length : int
The dimensions of the problem, should be the same used when creating the problem object
num_informants: int
The number of informants used for social component in particle velocity update
Public Methods
-------
improve(follow_current, follow_personal_best, follow_social_best, follow_global_best, scale_update_step)
Update each particle in the swarm and updates the global fitness
update_swarm(follow_current, follow_personal_best, follow_social_best, follow_global_best, scale_update_step)
Updates each particle, randomly choosing informants for each particle's update.
update_global_fittest()
Updates the `globale_fittest` variable to be the current fittest Particle in the swarm.
"""
def __init__(self, problem, swarm_size, vector_length, num_informants=2):
self.swarm_size = swarm_size
self.num_informants = num_informants
self.problem = problem
self.swarm = [Particle(self.problem, np.zeros(vector_length), np.random.rand(vector_length), i)
for i, x in enumerate(range(swarm_size))]
self.global_fittest = np.random.choice(self.swarm, 1)[0]
def update_swarm(self, follow_current, follow_personal_best, follow_social_best, follow_global_best, scale_update_step):
"""Update each particle in the swarm"""
for particle in self.swarm:
informants = np.random.choice(self.swarm, self.num_informants)
if particle not in informants:
np.append(informants, particle)
fittest_informant = find_current_best(informants, self.problem)
particle.update(fittest_informant,
self.global_fittest,
follow_current,
follow_personal_best,
follow_social_best,
follow_global_best,
scale_update_step)
def update_global_fittest(self):
fittest = find_current_best(self.swarm, self.problem)
global_fittest_fitness = self.global_fittest.assess_fitness()
if (fittest.assess_fitness() < global_fittest_fitness):
self.global_fittest = fittest
def improve(self, follow_current, follow_personal_best, follow_social_best, follow_global_best, scale_update_step):
"""Improves the population for one iteration."""
self.update_swarm(follow_current, follow_personal_best, follow_social_best, follow_global_best, scale_update_step)
self.update_global_fittest()
size = 25
vector_length = 2
num_informants = 2
pso = PSO(problem, size, vector_length)
# Interaction
We’re using Panel (a library from Anaconda) for the sliders and buttons. Because there are a lot of settings for PSO, we’ll leave a escape hatch for people in the form of a reset_button which will set the sliders to their default.
Sliders and defaults#
default_pop_size = 25
default_time = 3
default_num_informants = 6
population_size_slider = pn.widgets.IntSlider(name='Population Size', start=10, end=50, value=default_pop_size)
time_slider = pn.widgets.IntSlider(name='Time Evolving (s)', start=0, end=15, value=default_time)
num_informants_slider = pn.widgets.IntSlider(name='Number of Informants', start=0, end=20, value=default_num_informants)
default_current = 0.7
default_personal_best = 2.0
default_social_best = 0.9
default_global_best = 0.0
default_scale_update_step = 0.7
follow_current_slider = pn.widgets.FloatSlider(name='Follow Current', start=0.0, end=5, value=default_current)
follow_personal_best_slider = pn.widgets.FloatSlider(name='Follow Personal Best', start=0, end=5, value=default_personal_best)
follow_social_best_slider = pn.widgets.FloatSlider(name='Follow Social Best', start=0.0, end=5, value=default_social_best)
follow_global_best_slider = pn.widgets.FloatSlider(name='Follow Global Best', start=0.0, end=1, value=default_global_best)
scale_update_step_slider = pn.widgets.FloatSlider(name='Scale Update Step', start=0.0, end=1, value=0.7)
reset_params_button = pn.widgets.Button(name='Reset Parameters', width=50)
def reset_event(event):
global default_current
global default_personal_best
global default_social_best
global default_global_best
global default_scale_update_step
global default_pop_size
global default_time
global default_num_informants
follow_current_slider.value, follow_personal_best_slider.value = default_current, default_personal_best
follow_social_best_slider.value, follow_global_best_slider.value = default_social_best, default_global_best
scale_update_step_slider.value, population_size_slider.value = default_scale_update_step, default_pop_size
time_slider.value, num_informants_slider.value = default_time, default_num_informants
reset_params_button.on_click(reset_event)
Watcher(inst=Button(name='Reset Parameters', width=50), cls=<class 'panel.widgets.button.Button'>, fn=<function reset_event at 0x7fd552b0d5e0>, mode='args', onlychanged=False, parameter_names=('clicks',), what='value', queued=False, precedence=0)
Set the Target#
For the “click to set target” interaction, we’ll use a Holoviews DynamicMap. It sounds complicated but put simply, it links a stream with a callback function. In this case the stream we’re using is a hv.stream.SingleTap, which will trigger the tap_event callback function with the x and y position of the tap when a tap happens. A hv.Points object is returned which can be displayed later.
def tap_event(x,y):
global target_x
global target_y
if x is not None:
target_x, target_y = x,y
return hv.Points((x,y,1), label='Target').opts(color='r', marker='^', size=15)
target_x, target_y = 0.5, 0.5
tap_stream = hv.streams.SingleTap(transient=True, x=target_x, y=target_y)
target_tap = hv.DynamicMap(tap_event, streams=[tap_stream])
Layout everything together#
instructions = pn.pane.Markdown('''
# Particle Swarm Optimisation Dashboard
## Instructions:
1. **Click on the plot to place the target.**
2. Click '\u25b6 Begin Improving' button to begin improving for the time on the Time Evolving slider.
3. Experiment with the sliders
''')
dashboard = pn.Column(instructions,
pn.Row((vector_field*target_tap).opts(width=600, height=600),
pn.Column(
pn.Row(run_button, pn.Spacer(width=50), new_pop_button),
next_generation_button,
time_slider,
num_informants_slider,
population_size_slider,
follow_current_slider,
follow_personal_best_slider,
follow_social_best_slider,
follow_global_best_slider,
scale_update_step_slider,
reset_params_button)))
dashboard.servable()
Conclusion#
Particle Swarm Optimisation is a really intesting algorithm which was built while trying to build a simiplified model of social interactions. The original aim was to create an algorithm in which the particles would behave like flocking birds.
We’ve seen how each particle has a velocity and position, and the position represents a potential solution to your problem. For updating the velocities, each particle uses its current position, its own fittest position and the fittest positions of other particles.
We’ve also looked the HoloViz tools (Holoviews, Panel and Bokeh). Using these we build an interactive dashboard which shows all the particles updating!
Thanks for reading!